
Integration Off Abstract Data Model
There is a world outside data engineering, in Category Theoretical Mathematics, that's more efficient & powerful. Welcome to a world without ETL with always-on 100% fidelity to source data, metadata.


The moment ETL comes into play, the resulting data set is forever disconnected from source data and meta data. Of course one can add a hundred stitches, tools, AI to connect it back. But is this the only way? Is there a more effective and elegant to way achieve the same outcome without ETL? Especially, with disconnected metadata, anything relying the ETL’d data is stale in context. This is where Category Theoretical approach, designed for structure modelling and preservation, comes in handy. This is an attempt to relook at data modelling at a fundamental level - creating a foundation for ETL-free, always-on data integration with 100% fidelity to source data, data model, metadata and any related changes.
The challenges of enterprise integration (both for EAI and BI) are well documented highlighting the ridiculous amounts of time and monies burnt, most of which can be traced back to lack of consensus on common, shared data model or the rigidity of the agreed commonality that cannot accommodate the inevitable changes over time. The Category Theoretical approach enables an approach to create data model abstraction and allows any data model to have its own existence independent of implementation, unleashing immense business value not possible with conventional data engineering.
This document describes Integration Off Abstract Data Model (IOADM) – an approach to Enterprise Integration ‘anchored to Abstracted Data Models’, laying a foundation for ETL free, always-on data integration with 100% fidelity to source data, data model, metadata and any related changes.
This approach enables Enterprise Integration through a Data Model Abstraction that is portable, composable, extensible and reusable, alleviating integration-related time, and cost challenges. This also facilitates free movement of ETLs from proprietary to open source formats, aids in migration to Cloud, lays the foundation for related extensions – like data privacy, data residency, regulatory compliance etc.
Traditional integration approaches resulted in information silos, which is an unintended artefact of the conventional data modelling approaches that results in incompatible (cannot be mixed with other projects’) data models. The most important starting point for any enterprise integration project is a data model that captures the business intent in the context of data sources. Given the central role the data model plays, almost all enterprise integration challenges can be traced back to data model related issues, as below. It needs a bit of conscious unlearning to appreciate these as challenges:
Data Models, which represent the contours of business context and the business problem being solved with integration projects, are trapped and lost inside the proprietary data models of vendors or individual projects. The same model cannot reused.
These models cannot be ported to other platforms without expensive manual efforts. The models are not portable even within same database environment. Porting across different data model types gets lossy and time-consuming. This is even worse with porting across vendors’ proprietary models. They are not interoperable among different types of data models.
Commercially, enterprises are stuck with vendors’ expensive license costs and are increasingly trying to switch (to open-source or Cloud platforms) but bogged down by prohibitive proprietary data model migration costs.
Instead of planned reusability, heavy reliance on ‘accidental’ data commonality across disparate data sets.
Lack of abstracted separation (among source models, transformations, target models) is restrictive. The underlying data models are often so specific that the ETL procedures need to be tuned considerably when applied to another data source. This proves to be awfully expensive in special cases (scientific, pharmaceutical and consumer behaviour research studies).
Data Models traditionally did not have an independent existence outside the databases. Once data are materialized over a data model, rest of the programmatic interactions are directly with data. The need for structured metadata is intensifying only recently due to emerging critical business needs like data privacy, federation, residency etc. Such needs cannot be addressed with the traditional models without touching the source data every time for every different purpose.
Context of business intent gets locked in the heads of a few developers involved in the data model definition. This knowledge is lost, besides the information lost in hidden extracts and transforms to various models.
Even when the knowledge is documented or original development teams are available, Data models are not reusable. They are not extensible without expensive development efforts which also tend to disrupt business continuity.
Not composable – any enterprise environment is a composition of blocks of knowledge, but prevalent integration practices leave hundreds of overlapping knowledge blocks for lack of composability in data modelling.
The challenge is not just the contextual knowledge locked in data models that need abstraction, but also the repercussions of integrating off such locked data models, like the resulting inability to address several critical, emerging data related business scenarios. These gaps are addressed by the capabilities of Category Theoretical approach.
Brief commentary of current state: Several vendors have proprietary data models that reflect all the challenges discussed above. Portability of data models is not encouraged by design. A few vendors provide various templates to expedite integration projects but these templates themselves are locked in proprietary models.
A few have Common Data Model driven mapping to standard pre-defined entities but this is not flexible, dynamic and works only with vendor’s own ecosystem.
There are some attempts at using graph data models to achieve data model unification but do not address abstraction. Some techniques for Data Model Translation (Schema translations) exist through XML but these are not data model abstractions, not connected to the source data and the flexible data modelling, data lineage, programmatic transformations and data sanctity properties associated with the Category Theoretical approach are not present.
A way out:
While it suits some to keep the data models locked, anchoring all integration activities around an abstracted, reusable, extensible data model goes beyond solving the above issues and unlocks unprecedented business value.
The solution is not simply a layer of abstraction that liberates the data models but
Introducing a hygiene of re-thinking data modelling approach as reusable, composable, extensible, portable, and how this affects the many touch points of such data models.
Facilitating the numerous enterprise integration and data usage capabilities unleashed by this abstraction.
The vision of this approach is to affect a way of thinking that impacts application design, query design and even UI design for the target applications. The will eventually lead the industry in this direction with great many extended benefits discussed below.
This IOADM approach has layers of functionality exposed through user interfaces to,
Connect with data sources or metadata sources, data models in 3rd party systems,
Allow the users to view, explore source schemas and Categorical Query Language CQL converted source schemas (Candidate Schema),
Collaboratively evolve candidate schemas working on a shared artefact among different teams like data analyst, business analyst and programmer teams etc,
Define target data models. This establishes the Abstract Data Model that powers further business scenarios.
The same can also be achieved by importing 3rd party or proprietary models from Informatica, Power BI etc, converting data models locked in proprietary systems into extensible, reusable, composable Abstract Data Models, unlocking interoperability and collaboration.
More importantly, integrating off this Abstract Data Model unleashes business value through various use cases as below.
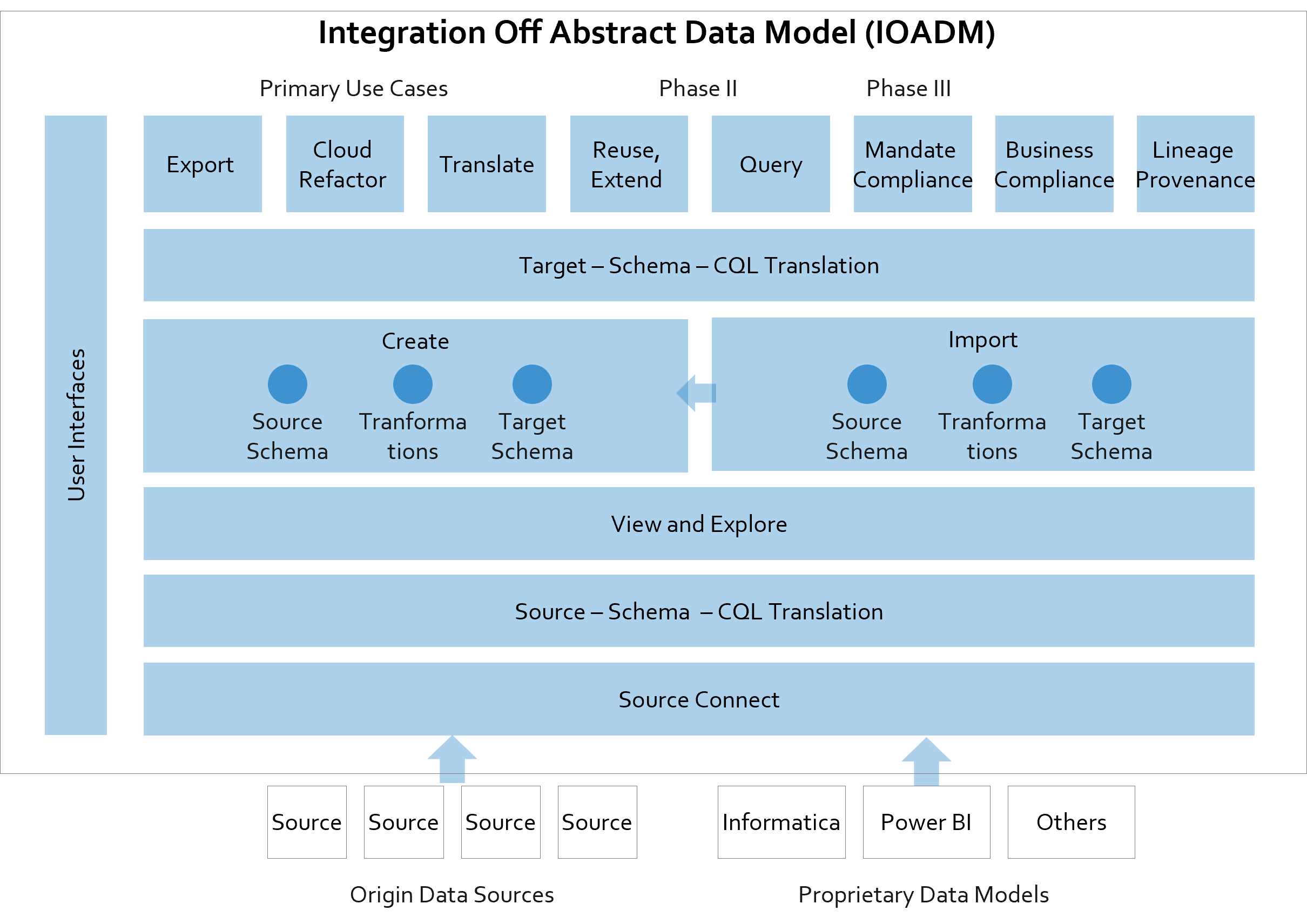
Export Module: The proprietary data models locked in vendor schema like Informatica or Power BI, can be exported to any target of choice. Porting the model from Informatica to Spark will save license costs and make the models reusable for other platforms in future as business demands, e.g. re-migrate to Teradata. This will also save significant manual migration costs, time, and associated errors.
Cloud Refactor Module: Several organizations are transitioning to Cloud services both on the source side (source side persistence moved to e.g. Azure SQL DB) and on the target side (to Teradata on AWS), necessitating a complete revisit of source schemas, targets schemas and transformations for every source-destination combination, resulting in time-consuming manual efforts. The capex to opex switch of Cloud services has only expedited this need. This module can automate and expedite the whole process and buffer the transitions across source-destination combinations.
Translate Module: Businesses having complex environments with multiple integration platforms / BI systems need to translate among proprietary models, across versions and reuse the constituents (source schema, transformations etc.). Translate Module addresses this need by translating and exposing the constituents of one model (e.g. Informatica model) to be explored in other environments (e.g. non-Informatica), providing access to metadata (schema), source extracts, target data loads and common transformations. This saves the heavily manual, error prone approaches prevalent and even entirely obviates a few steps – e.g., mapping of source schema by data analyst several times, the same activity repeated by integration developer several times, both disconnected and introducing mapping errors en route.
Extend Module: Stability of enterprise integrations depends on the stability of the Data Model, that need not be dropped with business changes – incremental or otherwise. This module delivers the functionality required to enable Abstract Data Models to be used for incremental enterprise integrations, infusing a new life into the stability of such integrations, leveraging composability.
Query Federation: This module delivers the functionality required to achieve database virtualization by querying off CQL schema with query federation; query performance enhancements by leveraging CQL native advantages like the dot operator; and implementing MPP querying by prefetching data subsets using data relationships.
The IOADM approach also enables the below use cases not possible with conventional integration approaches:
‘Enforcing’ mandate compliance during execution (e.g. GDPR, PII), capturing exceptions before committing.
Enforcing business rules (e.g. cross-tenanted applications’ data exposure), avoiding post facto legal hassles.
Maintaining and translating extended lineage requirements for data-sensitive scenarios (source data lineage and transformation lineage that make the research results replicable across original, changed or incremental data sets), preventing information loss during transformations and saving significant manual efforts in scientific, pharmaceutical and consumer behaviour research etc.
Complex ‘structure-preserving data integration operations’ with assurances of ‘data quality by construction’ (during data transformation or mapping) allowing heterogeneity of exposure in different data sources.
Value Impact:
Several studies show the extent of these challenges and their impact on business outcomes that can be addressed with this approach:
70% of all system integration projects fail to achieve the goals set for the project https://www.youredi.com/blog/10-reasons-why-integration-projects-fail
66% of companies lose up to $500K annually. 10% lose $1M or more for poor integrations. The 2021 State of Ecosystem & Application Integration Report
https://resources.cleo.com/report-ecosystem-and-application-integration-2021
95% surveyed companies strive to enable their business ecosystems, but 38 percent lack confidence to support the integration initiatives foundational to doing so. TMForum Digital Transformation Report, SDxCentral Report; McKinsey.
Collaborative mapping with canonical meaning of business data is a catalyst in triggering network dependent technologies like Blockchain or data-quality intensive technologies like AI.
Reusable data integration models can significantly cut the above time and cost challenges of data integration projects.
The flexibility of the underlying reusable data model can base continuous process change, decision models, and proactive actions on this unified view.
Note: The above concepts, applications, user experience examples are protected by Intellectual Property Rights owned by Surendra Kancherla.